
Авторы: Олег Бройтман и Русскоязычная Группа Пользователей Python и Zope.
ВВЕДЕНИЕ --------
Zope - это объектно-ориентированная платформа, сервер приложений, предназначенный для создания динамических web-приложений и интерактивных сайтов.
У выражения "объектно-ориентированный" здесь несколько сторон. Во-первых, Zope написан на языке Python, объектно-ориентированном языке со множественным наследованием.
Во-вторых, Zope построен вокруг идеи "публикации объектов" - URL, к которому обращается браузер, является ссылкой на объект (экземпляр класса), вызываемый на выполнение.
В-третьих, сами объекты (сериализованные экземпляры классов) хранятся в объектно-ориентированной базе данных ZODB.
Zope - это не цельный кусок софта, а богатый набор модулей, компонент.
ПОЧЕМУ Zope ------
Протоколы WWW (HTTP, CGI и т.д.) часто неадекватны задачам и могут делать публикацию динамических данных неоправданно сложной. Их низкий уровень недостаточен для непосредственного создания многих классов web-приложений на их основе.
Zope создает объектно-ориентированную оболочку вокруг этих низкоуровневых средств. С его помощью решение задачи происходит обычным путем - программист пишет набор иерархий классов, являющийся абстракцией предметной области, а Zope берет на себя труд по предоставлению доступа к экземплярам этих классов.
ПОЛЬЗОВАТЕЛИ Zope ------------
C Zope работают следующие категории пользователей:
Это, конечно, не обязательно разные люди - это роли. На маленьком сайте эти роли может выполнять один человек. Для больших сайтов Zope предоставляет механизмы делегирования полномочий администраторам участков сайтов, верстальщикам, редакторам.
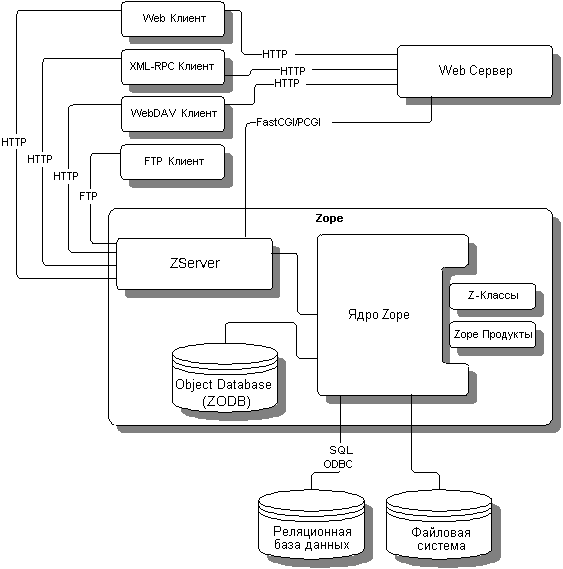
В "сердце" Zope находится ORB (object request broker), а также механизмы, обеспечивающие поиск (ZCatalog), безопасность, коллективную работу и разделение информации. Zope имеет web-интерфейс для программирования и администрирования.
Многопоточный ZServer предоставляет гибкий механизм связи, поддерживая протоколы HTTP, FTP, XML-RPC, FastCGI и PersistentCGI. Zope может быть запущен с ZServer, причем можно использовать ZServer совместно с уже существующим WWW сервером; или же Zope можно запустить из-под существующего WWW сервера в режиме PCGI (однопоточный сервер PersistentCGI).
Объектно-ориентированная база Zope хранит объекты (именно объекты в смысле Python, то есть сериализованные экземпляры классов); сама ZODB написана объектно-ориентированно, то есть как набор деревьев классов. В ZODB можно произвольно менять класс StorageManager - хранилище. Стандартное хранилище FileStorage хранит данные в файле Data.fs, но можно использовать альтернативные классы - SQLStorage, BerkeleyStorage и т.д. ZODB поддерживает атомарные операции (транзакции), неограниченный undo (только с соответствующим хранилищем, например, FileStorage или InterbaseStorage поддерживают Версии и откат, а некоторые другие хранилища - нет), приватные Версии, и масштабируется до гигабайтов хранимых данных. Отдельный механизм ZEO (Zope Enterprise Option) позволяет повысить надежность и масштабируемость путем кластеризации. Собственно, ядром ZEO является еще одно хранилище ServerStorage, которое обращается не к локальному Data.fs, а к удаленному серверу; вторым компонентом ZEO является как раз сервер.
Zope имеет уровень абстракции ZSQL, позволяющий легко интегрировать систему с SQL, будь то PostgreSQL, Oracle, MySQL или ODBC.
Zope держит пул открытых коннекций к SQL-серверам, дает из этого пула по требованию программы свободную коннекцию, закрывает их по таймауту, и открывает новые по необходимости.
Продукты - компоненты, написанные программистом на Питоне - позволяют дополнять Zope новыми типами объектов. Например, компонент (назовем его условно Poll) для создании на сайте голосований. После того, как программист напишет соответствующие классы, webмастер расставит экземпляры этих классов на сайте и создаст каждому из экземпляру дизайн; редактор сайта наполнит их содержимым (вопрос и список ответов для каждого экземпляра); и посетители сайта могут начинать голосовать!
Z-Классы - это механизм программирования "мышкой", программирование без программирования. Z-Классы не требуют знания программирования, и в то же время позволяют создавать новые типы данных (компоненты) через web. Z-классы легко распространяются и устанавливаются.
Document Template Markup Language (DTML) За этим названием скрывается богатый механизм интерпретации (рендеринга) шаблонов. Простые сайты можно создавать, вообще не обращаясь к Питону - на одном DTML (естественно, пользуясь, уже готовыми компонентами Zope).
ЧТО ДАЕТ Zope --------
Программисту:
web-мастеру:
администратору:
ПРОГРАММИРОВАНИЕ для Zope ----------------
Программирование для этой сложной и гибкой платформы осуществляется разными механизмами и на разных языках.
1. Программирование на DTML. Это не столько программирование, сколько верстка, работа webмастера. Из DTML доступно большое число функций и объектов Питона и Зоп, за исключением тех, которые скрыты по соображениям безопасности. DTML предназначен преимущественно для презентации, а не для манипуляции данными.
2. PythonMethods. Код пишется на Питоне и вводится через web-интерфейс Zope. На этот код распространяются те же ограничения безопасности,что и на DTML. Обычно PythonMethod - одна или несколько простых функций.
3. ExternalMethods. Это тоже код на Питоне, и тоже обычно несколько связанных функций. На этот код не распространяются ограничения безопасности (в том смысле, что этот код имеет доступ ко всем функциям, типам и классам Питона и Zope, но сам этот код можно защитить от добавления или использования средствами безопасности Zope), и ставится он в файловую часть Zope руками администратора хоста, а потом добавляется в иерархию объектов Zope через web-интерфейс.
4. Компоненты. Они пишутся на Питоне с помощью Product API. Компонент - это класс или набор деревьев классов. Никаких ограничений по безопасности (в уже указанном для ExternalMethods смысле; использование же методов компонента может быть защищено совместными усилиями программиста и администратора сайта). Код этот ставится в файловую систему администратором хоста, и Zope приходится перезапускать. После этого в списке Продуктов появляется новый Продукт (а то и не один, если программист или администратор хоста разом инициализирует несколько Продуктов или в одном Продукте регистрирует несколько Производителей (конструкторов)), экземпляры которого можно создавать в любом месте иерархии объектов.
4. ZClass. "Программирование мышкой". Создатель Z-класса расписывает, какие у объекта есть атрибуты, и создает на DTML способы редактирования и показа экземпляров класса. Все "программирование" идет через web-интерфейс Zope. Z-Класс добавляется в список Продуктов, и можно создавать его экземпляры. При изменении программистом Z-класса все экземпляры меняются автоматически (то есть экземпляры содержат не копию кода, а ссылку на класс). Z-Классы можно наследовать от богатого базового набора классов Zope, можно от других Z-классов, и программист может создать Компонент, включающий классы, от которых можно наследовать Z-классы.
ПУБЛИКАЦИЯ ОБЪЕКТОВ -------------------
Zope публикует Питоновские объекты (экземпляры классов). Для этого в Zope есть компонент ZPublisher - брокер объектных запросов. Получив запрос (от ZServer'а, который в свою очередь получает запрос из внешнего мира по одному из поддерживаемых протоколов), он:
Без помощи со стороны программы ZPublisher, конечно, не может осуществить подходящие преобразования типов, поэтому автор может указать, в каком виде он хочет получить данные. Вот пример формы для заполнения, с указаниями, зашитыми в имена полей:
<FORM name="formA" action="myObject" method="POST"> <input type="text" name="age:int" size="2"> <input type="checkbox" name="category:int:list">K1 <input type="checkbox" name="category:int:list">K2 <input type="submit" name="manage_setAge:method" value="Установить"> <input type="submit" name="manage_delete:method" value="Удалить"> </FORM>
После заполнения формы в браузере и нажатия одной из кнопок ZPublisher преобразует введенные данные. Переменная age преобразуется в целое, checkbox'ы - в список целых, и вызовется один из методов объекта myObject в зависимости от нажатой кнопки.
Проверка, естественно, осуществляется на стороне сервера, в Zope. Если переменная age не преобразовывается в целое, возникнет ошибка. Ее может обработать публикуемый объект, а нет - Zope выдаст пользователю HTML с текстом об ошибке. Для проверки на стороне клиента можно использовать JavaScript. Искривленные имена слегка мешают доступу из JS, но это не смертельно - к элементу форму можно добраться через массив elements: object = document.forms["formA"].elements["age:int"]
Как именно вызовется метод, зависит от его (метода) сигнатуры (в Питоне вся информация о коде доступна во время выполнения). Например, если myObject - экземпляр вот такого класса:
class AgeManager:
def view(self, age=None):
if age is None:
age = self.age
return "Возраст: <b>%d</b>" % age
def manage_setAge(self, age):
self.age = age
def manage_delete(self, category):
for c in category: self.delete(c) # self.delete не показан
то метод manage_setAge вызовется с целым age, или manage_delete - со списком нажатых checkbox'ов. Остальные переменные формы можно извлечь из общего пространства имен, доступного через self.
Публикация через метод GET и того проще: на запрос http://www.my.server/root/subobject/sub2/myObject/view?age:int=12
ZPublisher обходит иерархию объектов (траверс с учетом механизма acquisition, о чем позже) и публикует myObject - у объекта вызывается метод view с целочисленным параметром.
ACQUISITION - заимствование вместо наследования -----------
Acquisition - это механизм запроса значений переменных из текущего контекста. Переведем это слово как "заимствование" атрибутов; относительно адекватный перевод.
Заимствование значения атрибута происходит из контекста объекта. Контекстов бывает два - статический, возникающий в момент создания объекта, и динамический, возникающий во время вызова метода объекта на выполнение. Откуда именно происходит заимствование - этим управляет программист при создании или использовании компонента.
Контекст - это стек, в котором происходит поиск атрибута. Например, если есть контекст [object, sub2, myObject] (на вершине находится myObject), и myObject запросил значение атрибута color, то поиск будет происходить в глубину стека. Сначала атрибут с таким именем будет искаться в myObject, если его там нет - поиск перейдет к sub2, потом к object.
Статический контекст - это путь от корня ZODB (ZODB, не сайта!) к объекту в иерархии объектов. Динамический контекст - это путь (стек), возникающий во время обхода иерархии объектов компонентом ZPublisher при обращении к объекту через URL.
Например, если есть путь /root/object/subobject/myObject, то это и есть статический контекст (точнее, контекстом является стек объектов [root, object, subobject, myObject]).
Динамический контекст зависит от URL. Если произошло обращение к адресу http://www.server/root/object/subobject/myObject, то в этом случае динамический контекст совпадает со статическим. Но при обращении к http://www.server/root/english/object/subobject/myObject (где english - папка в объекте root) контекст будет другой - в стек добавится объект english. Чтобы понять, на какое именно место englsih добавится, надо подробно рассмотреть процесс траверса. ZPublisher сам тоже использует механизм acquisition, так что в целом разбор адреса http://www.server/root/english/object/subobject/myObject происходит следующим образом.
Получив (от ZServer'а) путь /root/english/object/subobject/myObject, ZPublisher начинает обходить отдельные части пути, строя по ходу стек. Сначала стек пуст, затем к нему добавляется root (поиск начинается от корня ZODB, и проверяется, что объект с таким именем есть в корне), затем ZPublisher обнаруживает english и запрашивает его (с учетом заимствования); объект обнаруживается в /root и попадает в стек, затем идет object, который заимствуется не из english, а из /root, затем нормальным путем идут subobject и myObject. В данном случае стек просто совпал с URL. Но если бы в english был свой object, он бы заимствовался бы оттуда, а не из /root. И если бы в этом object не было subobject, то subobject опять заимствовался бы из /root (ели он там есть). В результате мы имели бы контекст (стек) [/root, /root/english, /root/english/object, /root/subobject, myObject]. И если бы myObject запросил атрибут language, отсутствующий в /root/subobject, он получил бы его из /root/english/object, а не из /root/object!
Таким образом, меняя порядок компонент в URL, программист может совершенно менять вид и содержание сайта, не дублируя при этом огромные куски кода или текста. Надо лишь произвести правильную факторизацию - разбить код и оформление на небольшие объекты, и строить контекст (он еще называется acquisition path - маршрут заимствования значений атрибутов).
Рассмотрим подробный пример. Два основных объекта Zope - это классы DTML Document и DTML Method, включенные в дистрибутив Zope. Они предназначены для разного типа использования. DTML Document хранит содержание, текст; его путь - заимствование из статического контекста. DTML Method предназначен для активных действий, он заимствует значения из динамического контекста. Еще есть класс Folder - папка. В ней хранятся другие объекты.
Пусть, скажем, Документ my.html начинается со стандартного заголовка, и заканчивается стандартным подвалом. На языке DTML это выражается как <dtml-var standard_html_header> и <dtml-var standard_html_footer>. Разместим эти объекты на небольшом абстрактном (то есть существующим только в наших головах) сайте. Пусть есть корень (корень в ZODB есть всегда), в нем несколько папок, скажем, Razdel1 и Razdel2, 2 Метода - header и footer, и в Razdel2 - наш my.html.
/
standard_html_header
standard_html_footer
Razdel1
Razdel2
my.html
Итак, браузер обращается к http://www.server/Razdel2/my.html. ZPublsiher строит контекст [/, /Razdel2, /Razdel2/my.html] и вызывает рендеринг my.html. Тот начинает рендерится, и в самом начале встречает <dtml-var standard_html_header>. Запрашивается значение заголовка. В my.html такого объекта нет, в Razdel2 нет, поиск переходит в корень - там такой есть. Он выполняется (рендерится), потом выполнение возвращается в my.html, потом footer - все.
Возьмем и добавим в Razdel2 другой header:
/
standard_html_header
standard_html_footer
Razdel1
Razdel2
standard_html_header
my.html
И опять обратимся к http://www.server/Razdel2/my.html. Теперь my.html позаимствует другой header, и выглядеть будет по-другому!
Добавим в корень новый раздел, с другими header/footer:
/
standard_html_header
standard_html_footer
Razdel1
Razdel2
standard_html_header
my.html
NewLook
standard_html_header
standard_html_header
И обратимся к http://www.server/Razdel2/NewLook/my.html. Будет ли my.html использовать header из NewLook? Нет! my.html - DTML Document, и всегда использует статический контекст. Его acquisition path всегда [/, /Razdel2, /Razdel2/my.html].
Добавим в Razdel1 объект DTML Method index.html
/
standard_html_header
standard_html_footer
Razdel1
index.html
Razdel2
standard_html_header
my.html
NewLook
standard_html_header
standard_html_header
И обратимся к http://www.server/Razdel1/index.html. Поскольку это Метод, то будет использован динамический контекст, но в данном случае он совпадает со статическим. А вот при обращении к http://www.server/Razdel1/NewLook/index.html динамический контекст будет другой, и index.html позаимствует атрибуты из NewLook - и будет выглядеть по другому!
Изменим сайт последний раз. Все удалим,
/
standard_html_header
standard_html_footer
Razdel1
index.html
Razdel2
my.html
и отредактируем header/footer, так чтобы они включали на сайте, скажем, левую колонку. Назовем ее left-column, и создадим ее в корне и в разделах:
/
standard_html_header
standard_html_footer
left-column
Razdel1
index.html
left-column
Razdel2
my.html
left-column
Теперь при вызове http://www.server/Razdel1/index.html будет показываться одна колонка, http://www.server/Razdel2/my.html - другая. А header при этом один на всех! Как header знает, какую колонку использовать? Очень просто - он участвует в поиске по acquisition path, по контексту (статическому или динамическому в зависимости от того, откуда его вызвали), не более того.
Эти разные left-column даже не обязаны даже быть экземплярами одного класса. В корне это может быть DTML Method, а в Razdel2 - ZNavigator. Header'у все равно, кого рендерить, он вызывает left-column, ничего не зная об его типе и устройстве (опять объектно-ориентированное программирование).
Еще один пример, ближе к реальной жизни с Zope, но менее подробный. Предварительное замечание: когда URL ссылается не на метод объекта, а на сам объект, у него вызывается метод index_html.
Создадим маленький сайт. В корень поместим DTML Method index_html простого содержания:
<dtml-var standard_html_header> <dtml-var content> <dtml-var standard_html_footer>
и DTML Document content, хранящий собственно содержание раздела, вообще без заголовка/подвала.
/
standard_html_header
standard_html_footer
index_html
content
Razdel1
content
Razdel2
content
Обратимся к корню сайта: http://www.server/. Корневая папка вызовет свой index_html, который интерпретируется, подгрузит соответствующие заголовок и подвал. Ничего особенного.
Теперь обратимся к одному из разделов: http://www.server/Razdel1/ Этот папка, поэтому она вызовет свой index_html... Но в Razdel1 нет своего index_html. Он заимствуется из корня! Ну, и поскольку он DTML Method, то он сам заимствует атрибуты из динамического контекста. Header/footer возьмутся из корня, а content из Razdel1.
Третий, и последний пример совсем кратко. В папке db лежат dtml-методы (пусть dtml-методы будут называться db/view, db/insert, db/update), и sql-методы, которые параметризованы (имя таблицы, имена столбцов).
Далее, внутри этой папки делается папка, например users. В ее атрибуты прописываются конкретные параметры для методов (имя таблицы, имена столбцов).
По обращению db/users/view - получаем готовую страничку с содержимым таблицы. Метод view (равно как и insert и update) унаследован из db, но заимствует атрибуты из users.
Метод db/users/insert (унаследованный из db) прочтет из свойств папки db/users название таблицы, названия полей, и сконструирует форму, для добавления записи. То же будет происходить с другими папками, и их свойствами. В ходе развития проекта, точно так-же как и для случая ОО программирования, добавление новых методов в "базовый объект" db (например нужно будет сделать поиск - db/search) автоматически расширит функциональность "потомков" db/users, db/something...
SECURITY - механизмы безопасности в Zope --------
Zope предоставляет программистам и администраторам простые, и в то же время мощные и гибкие механизмы управления безопасностью. Безопасность в Zope стоит на трех китах, трех базовых понятиях - пользователь, роль, и вид доступа.
Вид, или тип доступа определяет программист при создании компонента. Каждому классу в компоненте определяется полномочие "Add" ("Добавить экземпляр класса в дерево объектов"), каждому методу класса можно определить свои собственные полномочия, которые определят, кому и какой вид доступа предоставлен к этому методу класса. Например, методу index_html (который вызывается при обращении к объекту, а не к конкретному методу) обычно дается вид доступа View. Но это дело программиста, как назвать свои полномочия, и какие методы какими полномочиями защитить. Обычно методы объекта объединяются в группы, предоставляющие один сервис. Например, класс НовостеваяЛента может иметь сервисы (группы методов) "показ новостей", "добавление новостей", "редактирование новостей", "удаление новостей", "добавление/редактирование/удаление рубрик". И каждый из сервисов можно защитить (дав ему отдельный вид доступа) - с точностью до одного метода. Для более тонкого управления, уже внутри метода, программист может запросить SecurityManager - "имеет ли текущий пользователь права на создание DTML Методов в Папке Razdel?"
Роли создает администратор сайта через менеджерский web-интерфейс Zope. Понятие роли распространяется не на весь сайт, не на ZODB, а на часть дерева. Администратор создает роль в какой-то папке, и дальше благодаря механизму acquisition эта роль распространяется вниз по поддереву.
Zope, поставленная из дистрибутива, имеет 3 роли, определенные в корне ZODB - Anonymous, Owner и Manager. Manager - это такой всесильный администратор, аналог рута. Owner - владелец тех ресурсов, которые он создал. Анонимный пользователь - просто посетитель сайта; ему изначально доступны типы доступа: Access content, View, Use SQL Methods (это для того, чтобы позволить вызывать SQL Методы из DTML Методов) и Search ZCatalog.
Администратор сайта в дальнейшем может создавать новые роли, как в корне, если у самого администратора есть права на редактирование корня, так и в любых поддеревьях, на которые у администратора есть права.
Эти 2 механизма - категории доступа и роли - совершенно ортогональны, и в web-интерфейсе образуют табличку из сотен checkbox'ов - какой роли какие категории доступа.
Администратор сайта может, например, завести роли Editor и ChiefEditor, и дать роли Editor права на редактирование DTML Document'ов, а роли ChiefEditor - права на редактирование DTML Method'ов, картинок, и на создание папок. Дав роли SubAdmin права на администрирование безопасности в поддереве сайта, администратор эффективно делегирует полномочия.
Пользователи (то есть записи о пользователях) - это объекты (как и все остальное), экземпляры класса User. Изначально Zope ставится с компонентом UserFolder, который хранит эти объекты в ZODB, и может получать и проверять username/пароль только по схеме Basic Authentication. Но компонентная технология и здесь дает свои преимущества. Уже доступны компоненты:
Все перечисленные компоненты умеют как Basic Auth, так и куки. На сайте можно расставить сколько угодно экземпляров разных компонент, и таким образом авторизовывать одну часть сайта из домена NT, а другую - из SQL. К сожалению, поставить в одну папку 2 разных UserFolder нельзя.
Тип доступа для пользователя проверяется не непосредственно, а через роли. Запись о пользователе (объект класса User), помимо логина и пароля, хранит список его ролей, и список доменов и/или IP, с которых пользователю разрешено работать.
Опять-таки, благодаря механизму заимствования, запись пользователя доступна и проверяется везде в поддереве, на вершине которого эта запись внесена.
Еще один механизм нужен, если какое-то привилегированное действие надо позволить совершить пользователю, не обладающему нужными привилегиями. Скажем, дать на просмотр (но только на просмотр) Документ, доступный только Менеджеру. Тогда это конкретное действие описывается (скажем, на DTML пишется Метод для просмотра), и этому Методу дается Proxy Role под роль Manager. Полный аналог юниксового setuid, и как со всяким setuid, надо быть очень внимательным, чтобы не насоздавать дыр в защите.
Наконец, последний механизм, Local Role, позволяет дать определенному пользователю дополнительные права (роли) на конкретный объект. Так-то роли даются пользователю там, где определена запись пользователя; Local Role позволяет определить дополнительные роли в контексте объекта, а не пользовательской записи. Локальные роли не заимствуются механизмом acquisition.
РУССКОЯЗЫЧНАЯ ГРУППА ПОЛЬЗОВАТЕЛЕЙ Python и Zope ----------------------------------
Приглашаем вас на наш сайт zope.net.ru. Наша группа отличается активностью и интересом к продвижению технологии Zope. Вы можете подписаться на наш список рассылки, послав письмо с телом (с телом, не с темой) subscribe python по адресу majordomo@list.glasnet.ru. Администратор списка - Евгений Двуреченский; хостинг списка - Россия-Он-Лайн.
В этой части статьи я расскажу и покажу, как создаются динамические сайты на примере сайта zope.net.ru; интерактива на сайте пока нет, но динамические объекты есть.
В целом сайт zope.net.ru не только community site нашей Группы Пользователей, но и реальный demo-site, на котором можно посмотреть, что и как устроено. Все "конечные" объекты (страницы, видимые пользователю) имеют ссылку "Показать DTML код объекта". Но многое остается скрытым. Здесь я, в частности, хочу прояснить то, что остается "за кадром" DTML кода.
УСТРОЙСТВО страниц ----------
Весь сайт совершенно динамический - генерится все, кроме картинок. Каждая HTML-страница на сайте генерится из множества объектов.
Каждая страница, очевидно, имеет стандартную обвязку (оформление) и уникальное содержание. Поэтому каждая страница сайта - это DTML Method стандартного устройства:
<dtml-var standard_html_header>
...здесь содержание страницы...
<dtml-var standard_html_footer>
standard_html_header - с чего начинается каждая страница сайта --------------------
Для работы многих объектов на сайте нужны различные переменные - тем или иным способом разобранный текущий URL. Zope предоставляет большую часть необходимой информации, но некоторые переменные для упрощения работы я вычисляю дополнительно. Поскольку они мне нужны на каждой странице, я их вычисляю в standard_html_header - в DTML Методе, который вызывается из каждой страницы. Полный код можно посмотреть:
<dtml-call "REQUEST.set('RealPARENT', PARENTS[-2].absolute_url())">
<dtml-if text-version>
<dtml-call "REQUEST.set('VirtualRoot', '%s/text' % SCRIPT_NAME)">
<dtml-else>
<dtml-call "REQUEST.set('VirtualRoot', SCRIPT_NAME)">
</dtml-if>
<dtml-call "REQUEST.set('RealURL', URL0[_.len(RealPARENT):])">
<dtml-call "REQUEST.set('URLn', _.string.split(RealURL, '/')[1])">
Здесь я вычисляю URL корня, отделяю его от path, и при необходимости (установлена переменная text-version) добавляю строку "/text"; это все для текстовой версии, подробности ниже. Плюс в URLn запоминаю первый объект в path после корня - это для горизонтальной навигации и тому подобного.
ГОРИЗОНТАЛЬНАЯ НАВИГАЦИЯ ------------------------
Очень простой DTML Метод global-nav, вызывается из standard_html_header:
<span class=nbar><nobr>
<dtml-if "URLn <> 'index_html'">
<a class=nbar href="<dtml-var VirtualRoot>/">В корень!</a> |
</dtml-if>
<a class=<dtml-if "URLn == 'About' ">highlight<dtml-else>nbar</dtml-if URLn> href="<dtml-var VirtualRoot>/About/"><dtml-if "URLn == 'About'"><font color="yellow"></dtml-if URLn>О нас<dtml-if "URLn == 'About'"></font></dtml-if URLn></a> |
<a class=<dtml-if "URLn == 'Python'">highlight<dtml-else>nbar</dtml-if URLn> href="<dtml-var VirtualRoot>/Python/"><dtml-if "URLn == 'Python'"><font color="yellow"></dtml-if URLn>Python<dtml-if "URLn == 'Python'"></font></dtml-if URLn></a> |
<a class=<dtml-if "URLn == 'Zope' ">highlight<dtml-else>nbar</dtml-if URLn> href="<dtml-var VirtualRoot>/Zope/"><dtml-if "URLn == 'Zope'"><font color="yellow"></dtml-if URLn>Zope<dtml-if "URLn == 'Zope'"></font></dtml-if URLn></a> |
<a class=<dtml-if "URLn in ('search', 'search-results')">highlight<dtml-else>nbar</dtml-if URLn> href="<dtml-var VirtualRoot>/search/"><dtml-if "URLn in ('search', 'search-results')"><font color="yellow"></dtml-if URLn>поиск<dtml-if "URLn in ('search', 'search-results')"></font></dtml-if URLn></a>
</nobr></span>
Я проверяю упомянутую URLn, если не index_html - значит рендерится не
корень, и я вставляю в HTML ссылку на корень. Затем по очереди проверяю
каждый из главных подразделов сайта, и подсвечиваю тот из них, в котором
находимся:
ВЕРТИКАЛЬНАЯ НАВИГАЦИЯ ----------------------
В самом начале существования сайта я не стал заморачиваться со сложной левой колонкой. Для начала я хотел, чтобы там был простой список подразделов текущего раздела, плюс ссылки на другие главные разделы сайта. Поскольку я хотел их писать в угодном мне порядке, я не стал обходить дозором сайт, а просто поместил в корень и в главные разделы сайта списки с именем left-col-list, и левая колонка (left-column) их заимствовала из текущего контекста. И идею, и способ реализации я подглядел на zope.org:
http://www.zope.org/Members/phd (см. левую колонку), http://www.zope.org/Members/phd/local_nav/view_source?pp=1
Альтернативным вариантом было бы промаркировать каждую из папок, которую я хочу поместить в навигацию, каким-нибудь атрибутом (скажем, left-col-view) и показывать в навигации папки не из заранее заготовленного списка, а те, у которых этот атрибут установлен. А для сортировки сделать этот атрибут не булевским, а числовым - весом. Но тогда неудобно сортировать список папок. Если мне надо поменять местами 2 папки, приходится открывать множество экранов и редактировать этот атрибут отдельно. Неудобно, поэтому я так и остался со списком left-col-list.
Через некоторое время существования сайта я решил, что хорошо бы левую колонку усложнить и сделать покрасивее. Пусть, скажем, корневые (главные) разделы сайта будут отдельно, а подразделы текущего раздела пусть вставляются в середину списка, да еще с отступом. Очень не хотелось дублировать информацию (то есть чтобы каждый left-col-list содержал в себе еще и пункты предыдущего уровня) - слишком сложно было бы для редактирования. Устройство данных и алгоритм вполне очевидны - надо просканировать все поддерево сайта от корня до текущей папки, найти все left-col-list и объединить их в иерархическую структуру - каждый left-col-list ищет себе место в предыдущем уровне. Написать такую конструкцию на DTML... наверно, можно было бы, но сложно. Тут в первый раз за все время существования сайта я обратился к Python и написал External Method. Его код есть на сайте:
http://zope.net.ru/Zope/navigation_left_column
Там простая рекурсивная функция default_render, которая обегает полученную структуру и рендерит ее в HTML, и собственно метод navigation_leftColumn обхода сайта от корня. В процессе его создания я столкнулся с необходимостью выключить acquisition - в данном случае он оказался излишним, ведь я хочу получать реальные left-col-list в их соответствующих папках, а никак не заимствованные! Очень хорошо, никаких проблем, Zope позволяет сделать и это. Я проверяю наличие объекта не в parent, а в parent.aq_explicit - подобъекте, в котором заимствование в точности выключено. После чего ренедерю DTML-объект left-col-list в питоновский список - для этого DTML-объект надо вызывать, передав параметрами текущий контекст: leftcol_list(self, _), и простым циклом ищу, куда бы этот список залинковать на предыдущем уровне.
Кончается все вызовом функции render. Сначала это был default_render, а потом я ее переписал на DTML, чтобы легче было редактировать:
<dtml-in alist> <dtml-let url="_['sequence-item'][0]" name="_['sequence-item'][1]" xplist="_['sequence-item'][2]"> <dtml-var "' ' * indent"> <a class=nbar href="&dtml-VirtualRoot;&dtml-url;">&dtml-name;</a><br> <dtml-if xplist><dtml-var "navigation_lcRender(this(), _, alist=xplist, indent=indent+4)"></dtml-if xplist> </dtml-let> </dtml-in alist>
В результате левая колонка свелась к простому коду
<span class=base><br><dtml-var "navigation_leftColumn(this(), _, navigation_lcRender)"></span>представляющему собой HTML-обрамление вызова navigation_leftColumn:

ВЕРСИЯ ДЛЯ ПЕЧАТИ и текстовая версия -----------------
На сайте, в объекте standard_html_footer есть ссылки на текстовую версию сайта и версию страницы для распечатки.
Изначально существовала только версия для распечатки. Реализована она крайне просто - в URL передается параметр pp (printable page), затем ZPublisher вводит эту переменную в пространство имен (в Zope это делается автоматом), а в standard_html_header/footer ее значение (на самом деле просто присутствие и отличие от нуля) проверяется. В случае отсутствия pp (или нуля) генерится полная версия страницы, со всем оформлением, а в случае присутствия - генерится страница только с содержанием, без оформления.
Затем один из членов нашей Группы, Денис Откидач, предложил добавить еще специальную текстовую версию. Отличие от версии для печати - в ссылках. В версии для печати все ссылки ведут на страницы с оформлением. А в текстовой версии все ссылки должны вести опять-таки на текстовые версии страниц.
Реализация текстовой версии прошла несколько этапов. Самым первым был вариант, когда средствами Апача все адреса http://zope.net.ru/text/(.*) переписывались в http://zope.net.ru/$1 с добавлением упомянутой переменной pp :) Это не вполне работало, потому что ссылки все еще были "не туда".
Нынешняя реализация проста до неприличия за счет использования acquisition. В корне сайта создана папка /text. Она совершенно пуста. Это ничему не мешает. Если рендерится http://zope.net.ru/ - то вызовется корневой index_html, а если рендерится http://zope.net.ru/text/ - то этот index_html позаимствуется из корня.
В чем тогда суть? А суть в том, что папке /text приписаны 2 атрибута - pp и text-version. Благодаря переменной pp Метод index_html, заимствованный из http://zope.net.ru/text/ будет рендерится без оформления (переменная pp в данном случае заимствуется из /text, а не передается через URL), в отличии от непосредственного вызова http://zope.net.ru/. А переменная text-version является флагом, благодаря которому standard_html_header добавит строку "/text" к переменной VirtualRoot. Ну и остается пройтись по сайту и заставить все ссылки на корень рендерится через VirtualRoot - тогда все ссылки в текстовой версии будут опять-таки вести на URL с префиксом "/text": http://zope.net.ru/text/
ПОИСК -----
В Zope есть встроенный механизм поиска - ZCatalog. Он не работает с морфологией, не ищет по регулярным выражениям; есть оператор *. Но! Есть у Z-Каталога одно большое достоинство - тесная интеграция с Zope. Я могу индексировать только определенные объекты, по дате, могу ограничиться только объектами, для которых у роли X есть право доступа Y и т.п. Кроме того, после индексации объекты сами говорят своим каталогам "я изменился - переиндексируй меня", о чем в htDig приходится только мечтать. Аналогично и при добавлении новых объектов и удалении старых - они посылают сообщение каталогу. Точнее, могут посылать - для этого их классы надо наследовать от CatalogAware.
Для начала работы надо добавить на сайт экземпляр или несколько экземпляров класса ZCatalog. Я добавил 1 в корень, и назвал его search-catalog. Затем сайт первый раз индексируется. Я проиндексировал полностью все объекты, у которых Anonimous имеет право View - хочу сделать публичный поиск. В процессе индексации Z-Каталог создает несколько индексов. Какие именно - дело менеджера. Я не стал менять умолчания, и поэтому у меня создались:
Форму для поиска я поместил в отдельный мелкий Метод
<FORM ACTION="&dtml-VirtualRoot;/search-results" METHOD="GET"> Искать <INPUT TYPE="text" NAME="text_search" VALUE="<dtml-var text_search missing>" SIZE="<dtml-var field_size missing=30>"> <dtml-if show_button> <INPUT TYPE="SUBMIT" NAME="Ok" VALUE="Найти"> </dtml-if show_button> </FORM>для того, чтобы иметь одну копию формы (с параметрами - показывать ли кнопку "Искать", и размер поля ввода), а саму форму вставлять в разные места.
Первое место, где эта форма используется - отдельная страница поиска http://zope.net.ru/search/. Устроена она просто:
<dtml-var standard_html_header>
<h2><dtml-var title_or_id> <dtml-var document_title></h2>
<p><dtml-var "_.getitem('search-form', 0)(_.None, _, show_button=1)"></p>
<dtml-var standard_html_footer>
Стандартное оформление плюс вызов упомянутого Метода с параметром "показать
кнопку".
Сам поиск реализован на DTML же... ну то есть на DTML написан вызов Z-Каталога и оформление результатов:
<dtml-var standard_html_header>
<h2><dtml-var title_or_id> <dtml-var document_title></h2>
<p><dtml-var "_.getitem('search-form', 0)(_.None, _, show_button=1)"></p>
<dtml-let catalog="_.getitem('search-catalog', 0)">
<dtml-if text_search>
<dtml-call "REQUEST.set('search1', catalog(PrincipiaSearchSource=text_search))">
<dtml-call "REQUEST.set('search2', catalog(title=text_search))">
<dtml-call "REQUEST.set('results', search1 + search2)">
<dtml-else>
<dtml-call "REQUEST.set('results', catalog(REQUEST=REQUEST))">
</dtml-if>
</dtml-let>
<dtml-if results>
<dtml-with results>
<p>Найдено <dtml-var "_.len(results)"> документов.</p>
<dtml-in results previous size=20 start=query_start>
<p class="small"><a href="<dtml-var URL><dtml-var sequence-query>query_start=<dtml-var previous-sequence-start-number>">(Предыдущие <dtml-var previous-sequence-size>)</a></p>
</dtml-in>
<table>
<dtml-in results size=20 start=query_start>
<tr valign=top>
<td class="listitem"><a href="<dtml-var VirtualRoot>/<dtml-var "getURL()[_.len(RealPARENT)+1:]" url_quote>"><dtml-var "getObject().title_or_id()" size=30></a></td>
</tr>
</dtml-in>
</table>
<dtml-in results next size=20 start=query_start>
<p class="small"><a href="<dtml-var URL><dtml-var sequence-query>query_start=<dtml-var next-sequence-start-number>">(Следующие <dtml-var next-sequence-size>)</a></p>
</dtml-in>
</dtml-with results>
<dtml-else>
<p>Не найдено ни одного документа.</p>
</dtml-if results>
<dtml-var standard_html_footer>
Сначала я получаю ссылку на сам объект каталог: catalog=_.getitem('search-catalog', 0), затем проверяю, был ли передан в форме параметр text_search. Если да - делаю 2 поиска по каталогу - по содержимому текстов (индекс PrincipiaSearchSource) и по заголовкам (индекс title). Результаты двух поисков склеиваю - это такой способ выполнить операцию OR. Операция AND поддерживается в таком виде: catalog(id="index_html", title="Python"). О памяти/скорости не беспокоюсь - ZCatalog полностью поддерживает lazy evaluation, и даже суммирование результатов не заставляет его грузить в память все объекты.
Если text_search не было - просто делаю пустой запрос к каталогу; при этом найдутся все объекты.
Ну и выдача результирующего HTML - простой цикл по списку результатов с разбивкой на страницы.
Текстовая версия тоже работает. Работает как переход их полной версии в текстовую, так и версия для распечатки, причем ссылки из текстовой версии результатов поиска честно ведут на текстовые версии документов. Я почему это подчеркиваю? Да потому что я потратил на текстовую версию не больше полчаса, и с тех пор пользуюсь результатами. Плюс еще минут 10 я потратил, чтобы передать запрос на странице результатов поиска в ссылки на текстовые и печатные версии.
НОВОСТИ и импорт новостей -------
Самой активной, часто меняющейся частью сайта являются разделы импортируемых новостей. Новости импортируются из источников по Питону и Зоп (плюс несколько других, менее интересных). Поток новостей идет в формате RSS 0.91. Разбором приходящего XML занимается компонент RSS Channel, он же и хранит список элементов потока, плюс простые DTML Методы для оформления результатов.
Импорт осуществляется по команде программы, запускающейся из cron несколько раз в сутки. Программы обращаются к сайту по HTTP. Это один из двух главных протоколов RPC, по которому можно обратиться к Zope (второй - это, конечно, XML-RPC).
Новости показываются в правой колонке сайта, кроме корня. В корне новости показывает корневой index_html: http://zope.net.ru/index_html/view_source?pp=1 В правой колонке новости показывает сам объект right-column: http://zope.net.ru/right-column/view_source?pp=1 Он создает HTML-оформление для right-col-news и показывает на каждой страницу стандартную картинку Zope. Сам он вызывается из standard_html_footer.
Если объект right-column на сайте один - в корне, то объектов с именем
right-col-news несколько - в корне и в каждом из главных разделов сайта.
Когда right-column рендерится, он заимствует нужный right-col-news из
текущего контекста. Так что при желании можно переопределить содержание
этой колонки в любом разделе:
http://zope.net.ru/Python/right-col-news/view_source?pp=1
http://zope.net.ru/Zope/right-col-news/view_source?pp=1
MAINTAINANCE (backup, pack Data.fs) ------------
Каждый сайт требует какого-то обслуживания, регулярной чистки, резервного копирования и т.п. Наиболее просто в Zope делается backup. Зоп позволяет проэкспортировать любой объект (вплоть до корня ZODB). Экспорт может сделать в файл ZEXP (внутренний формат ZODB) или XML. Любой из экспортных файлов потом импортируется назад, при необходимости. Более того, формат ZODB и ZEXP полностью переносим между всеми платформами и ОС. Можно проэкспортировать сайт с NT на AMD и проимпортировать на спарковый Солярис! Экспортный файл можно получить по сети (по HTTP) или сохранить в файловой системе сервера. Я запускаю backup из cron раз в неделю, экспортирую весь сайт в ZEXP (до создания поиска файл занимал 300K, вместе с каталогом он теперь чуть больше мегабайта), получаю его по HTTP и складываю на своей машине. Время от времени я запускаю backup руками - для того чтобы получить самую свежую версию и положить ее на локальный сервер для отладки.
Второй процесс, уже не относящийся непосредственно к сайту - упаковка файла Data.fs. Файл этот - физическое представление ZODB с хранилищем FileStorage. Достоинство этого хранилища - простота. Zope, поставленный из дистрибутива, работает именно с этим хранилищем. Есть и другие хранилища - BerkeleyStorage и пр. Их недостаток - отсутствие Undo и Версий. Есть хранилища типа InformixStorage и OracleStorage, поддерживающие Undo и Версии, но они требуют соответствующих SQL-серверов. Зато они не растут, как Data.fs, и не требуют упаковки. Хранилища без Undo тоже не растут.
Я пользуюсь FileStorage. Это хранилище держит всю ZODB в одном файле Data.fs (плюс индекс Data.fs.index, что здесь совершенно неважно). Файл этот растет - все транзакции FileStorage дописывает только в конец файла. Поэтому время от времени следует избавляться от старых транзакций - упаковать файл. Команда Pack в Зоп требует вещественного параметра - число дней, за которые оставить транзакции в базе. Я делаю упаковку раз в неделю, в понедельник ночью, оставляя транзакций за последние 3 дня. Это позволяет мне в понедельник утром сделать Undo операции, которую я совершил в пятницу. Команду Pack я также, конечно, вызываю из cron, по HTTP.
РЕЗЮМЕ и планы на будущее ------
В своем классе продуктов - сервера web приложений (web application servers) - Zope не уникальный продукт, но обладающий массой достоинств, которыми он меня привлек, и я использую Zope со все большим удовольствием. Тем более что разработчики Zope весьма открыты, и немало моих собственных патчей, и патчей, сделанных по моей просьбе, вошло в код.
Чего не хватает именно на нашем сайте - внятной content-модели, устройства документов. План, соответственно, таков - создать, или взять готовые, или довести до ума полуготовые Z-Классы, описывающие устройство документа (заголовок - содержание - автор - дата публикации - и т.п.), и перевести все нынешние простые документы в эту структуру. Проиндексировать Z-Каталогом по отдельным полям. Это позволит, например, запросить каталог "дай список всех авторов" (то есть уникальных входов в индекс author) и создать страничку "Все авторы", со ссылками на публикации каждого автора. В будущем, если количество авторов, пишущих для сайта, станет велико, можно будет создать полноценную CMS (content management system).